


Daylight社製品
(情報化学システム構築ツール)
tab:{
title:{概要}
概要
Daylight社製品は、インシリコ創薬および化学情報管理のシステムを構築するための開発用ツール群です。
以下から必要なコンポーネントを選択して導入いただけます。
パンフレット

Daylight社製品パンフレット(PDF、633 KB)
Daylight Chemical Information Systems社ウェブサイト
開発元であるDaylight社ウェブサイトもあわせてご覧ください。
title:{製品構成}
製品構成
分子構造データベースシステム THOR/Merlin
分子構造データベースTHOR/Merlinシステムと、THOR/Merlinシステムを使用するためのツール群です。
| THOR system | 分子構造および化学情報データベースの構築、データ登録および参照 |
| Merlin system | THORデータベースの高速検索および探索的データ解析 |
| Database Management Package | データベースシステムの管理ツール |
| Merlin Contorol Language | Merlin検索の自動化用スクリプト言語 |
| Reaction Package | 化学反応データベース機能 |
また、THOR/Merlinデータベースで利用可能なデータコンテンツも取り扱っています。
| データベース名 | データソース | 概要 |
|---|---|---|
| ACD (Available Chemicals Directory™) |
MDL | 48万件以上の重複のない、商業的に入手可能な化合物のデータベース |
| MEDCHEM | Biobyte Corp. | LogPやpKaが測定されたものも含め、総数5万5000件以上の化合物のデータベース |
| SPRESI | InforChem GmbH | 56万件以上の文献データから抽出された約380万件の化合物のデータベース |
| WDI (World Drug Index™) |
Derwent Publications | 約8万件の医薬品・薬理活性化合物データベース |

分子構造データ処理ツール
データベースシステムやツールキットの機能を補完し、より高度な機能を提供します。 以下のようなツールが含まれます。
- 分子構造データの形式変換(MDL/SD/RD形式、SMILES形式、TDT形式)
- 分子フィンガープリントの生成
- 互変異性体構造の生成
- 各種分子記述子やClogP、CMRの算出
- Daylight社製品の機能をウェブで利用するためのCGI
- など

ウェブサービス(ウェブアプリ用ライブラリ)
WebアプリケーションからDaylightソフトウェアの機能を利用するための、Javaで作成されたコンポーネント集です。
以下のようなコンポーネントが含まれます。
- SMILESの正規化(canonical SMILESへの変換)
- 与えられた化学反応(SMIRKS)に従ったSMILESの変換
- 分子構造データの形式変換(MDL/SD/RD形式、SMILES形式、TDT形式)
- 分子記述子やClogPなどの物性推算値の計算
- 分子構造の描画
- など

ツールキット(プログラミングライブラリ)
Daylight社製品の機能を提供するC言語/C++/FORTRAN用プログラミングライブラリ群です。
分子記述子や分子フィンガープリントの算出、THOR/Merlinシステムへのアクセスなどの機能を自作プログラムに組み込むことができます。

DayCart(データベースシステム用カートリッジ)
OracleおよびPostgreSQLデータベースに構造情報の格納・検索機能を追加するカートリッジです。

title:{基盤技術}
基盤技術
Daylight社製品で用いられている基盤技術をご説明します。
SMILESとSMARTS
SMILES: 分子記述言語
SMILES (Simplified Molecular Input Line Entry System) は、Daylight C.I.S.社の創立者である Dr. David Weininger が考案した分子記述言語です。
簡便でわかりやすく、定評ある分子記述法として広く普及しています。
- 分子の二次元構造を文字列として記述
- 情報をコンパクトに保存
- 原子座標の羅列と違い、ユーザーにも理解しやすい
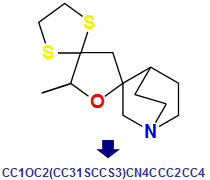
SMILESには以下の種類があります。
| generic SMILES | 原子とそれらの間の結合のみを記述したSMILESです。 先頭の原子、結合・原子を辿る順番、分岐での主鎖・側鎖の選択により、同一構造を複数のgeneric SMILESで表せることがあります。 |
| isomeric SMILES | 同位体や、不斉中心や二重結合周辺の立体配置の情報を含めたSMILESです。 |
| canonical SMILES | 一つの構造に対して一意になるよう、先頭原子、辿る順番、分岐の主鎖・側鎖を一定のルールで決定したSMILESです。 generic SMILESをcanonical SMILESに変換することを正規化(canonicalization)と呼びます。 |
| absolute SMILES | 正規化されたisomeric SMILESです。 |
Canonical SMILESは分子構造と1:1で対応するため、THOR/Merlinデータベースのキー項目として利用されます。
SMARTS: パターン記述言語
SMARTS (SMILES ARbitrary Target Specification) は、SMILESを検索クエリーように拡張したパターン記述言語です。
以下のような様々な条件を表記できます。
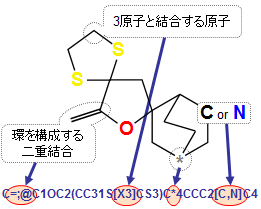
- 単純指定(芳香族炭素“c”、二重結合“=” など)
- ワイルドカード指定(水素以外の任意の原子“*”、任意の結合“~”)
- 条件指定(3原子と結合する原子“X3”、環を構成する結合“@” など)
- 上記の組み合わせ指定(非芳香族の炭素または水素“[C,N]”、環を構成する二重結合“=;@” など)
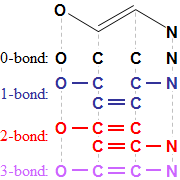
分子フィンガープリント
Daylight社製品の分子フィンガープリントは、高速で汎用的な計算方法により、検索の候補分子の絞り込みや分子の類似度の算出に利用できます。
- 結合に基づく分子パターン情報
- 特定の部分構造(官能基など)に依存せず、分子全体の構造を反映
- わずかな構造の差異にも敏感なため、コンビケムライブラリーの絞り込みなどに威力を発揮
- 高速な検索
- フィンガープリントの比較はビット演算のため、処理が極めて高速
- SMLIESやSMARTSによる構造の比較の前にフィンガープリントで候補を絞り込むことで、構造検索の所要時間を大幅に短縮可能
- 可変長フィンガープリント
- 結合パスの最大長の指定により、フィンガープリントのビット長が変化
- 長ければ情報量優先、短ければ省スペース・高速化。用途に合わせて自由に長さを調節可能
- 長いフィンガープリントは短いフィンガープリントに変換可能
Superstructure検索とSubstructure検索
Daylight社製品には、一般的な構造検索と異なり、二種類の構造検索が用意されています。
- Superstructure検索
- Superstructure(クエリー構造のスーパーセット、すなわちクエリー構造を部分構造として含む構造)を検索します。
- 一般的な用語での部分構造検索に相当します。
- Substructure検索
- Substructure(クエリー構造のサブセット、すなわちクエリー構造の部分構造)を検索します。
- クエリー構造の合成に必要な試薬の探索などに利用できます。
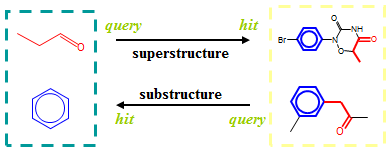
共通部分構造の抽出
入力した複数の構造の中で、共通している部分構造を抽出することができます。抽出された部分構造は、SMARTSとして得られます。
また、この機能を利用した凝集型クラスタリングツール sdclusterも用意されています。
THORとTDT
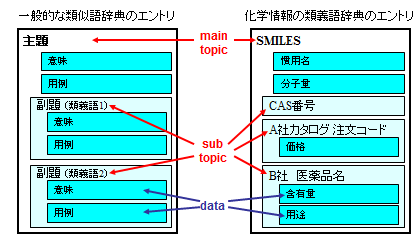
THOR (THesaurus Oriented Retrieval)
THORデータベースは、分子構造や物性値、注文番号などの情報を、類義語辞典のように階層状に分類して整理します。
main topic
- 類義語辞典では主題で、エントリー内の項目はすべてmain topicに関連する内容です。
- THORでは、化合物を特定する情報として、分子構造を表すSMILESがmain topicです。
sub toipc
- 類義語辞典では副題で、main topicの意味を表す別の表現です。
- THORでは、化合物を特定できる別の情報として、CAS番号や試薬会社の注文コード、医薬品名などがsub topicになります。
data
- 類義語辞典では意味や用例で、main topicやsub topicの内容が記載されます。
- THORでは、
- 化合物自身の情報である、慣用名や分子量などの物性は、main topicのdata
- 試薬の価格などは、sub topic “A社カタログ 注文コード”のdata
- 医薬品の用法などは、sub topic “B社 医薬品名”のdata
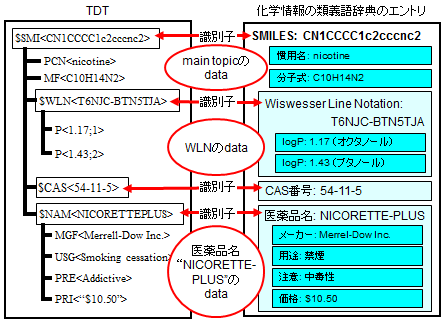
TDT (THOR Data Tree)
TDTは、Daylight社製品独自のデータベース形式です。THORシステムは「化学情報の類義語辞典」をTDT形式で実現します。
- XMLライクなツリー構造
- main topicを根に、sub topicを節に、dataを葉にしたツリー構造です。
- 記述の順序によって根-節-葉の親子関係を規定します。タグの入れ子関係などの複雑な記述は不要です。
- 識別子
- THORシステムは、main topicとsub topicを識別子としてTDTのエントリーを参照します。
- 「重複がなく一意に決まるもの」や「ユーザーが扱いやすい文字列や番号」が識別子に向いています。
- 柔軟なデータ格納
- バイナリ形式を含めた任意の形式のデータを格納できます。
- 関連する情報を同じ項目にまとめて格納できます。
例: logPの項目に「logP値」 「溶媒」をまとめて保存します。 - 同じ項目を、共通の項目名で複数作ることができます。
例: 異なる溶媒のlogP値を、同じ項目名“logP”で別々に保存します。 - エントリごとに保存するデータ項目が異なっていても、余分な保存領域は発生しません。
- データ計算、解析プログラム群
- TDTに対してデータを計算・解析し付加するプログラム群があらかじめ用意されています。
- SMILESからフィンガープリント、ClogP・CMR、各種分子記述子などを導出して付加できます。
- SMILESから互変異性体を網羅的に導出して付加できます。
}:tab