


MOE - 構造バイオインフォマティクス
tab:{
title:{概要}
MOEには、タンパク質/核酸の配列アラインメントと構造の重ね合わせの機能があり、配列と立体構造の比較を容易に行えます。構造の重ね合わせを基に保存領域を抽出することもできます。ホモロジーモデリング用の構造データベースや創薬・生命科学において重要なファミリータンパク質の構造データベースも搭載されており、これらに対して様々な条件で検索し、データマイニングを行えます。配列非依存的なタンパク質の類似構造検索もできます。
title:{配列と立体構造のアラインメント}
アミノ酸/核酸配列アライメント
MOEは独自の配列と立体構造を考慮したタンパク質/核酸アラインメント手法を搭載しています。この手法は1対1のアラインメントだけでなく、複数のタンパク質/核酸を同時にアラインメントすることもできます。複数の多量体の配列から分子鎖ごとにサブユニットを定義することで、サブユニットごとのアラインメントが可能です。配列の一部分や2次構造の重み付け、拘束を考慮したアラインメントが可能です。アラインメントの中で配列のみのデータと構造データを混ぜることによって、構造未知の配列データに対して、信頼性のある推察を得ることができます。核酸では5’-3’あるいは3’-5’の順序を切り替えてアラインメントが可能です。
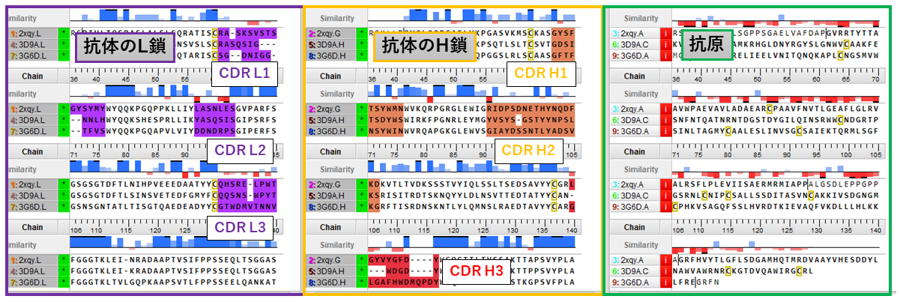
3つの抗体-抗原複合体の配列アラインメント。抗体のL鎖(紫)、H鎖(橙)、抗原(緑)を3つのサブユニットに分けて、それぞれをアラインメントし重ね合わせを実行。CDR L1-3とCDR H1-3は、抗体の抗原認識領域。
タンパク質/核酸構造の重ね合わせ
タンパク質/核酸の立体構造の重ね合わせを行い、その結果をレポート形式で出力します。PDB IDなどでタンパク質に関連付けられたリガンドや溶媒などは自動的にタンパク質に追従して重ね合わせられます。また、多量体同士をまとめて重ね合わせたり、受容体ポケット構造など注目している残基セットのみを利用した重ね合わせも行えます。レポートでは重ね合わせ全体のRMSDだけでなく、残基毎のRMSD値がグラフ表示され、構造の異なる残基を容易に検出できます。
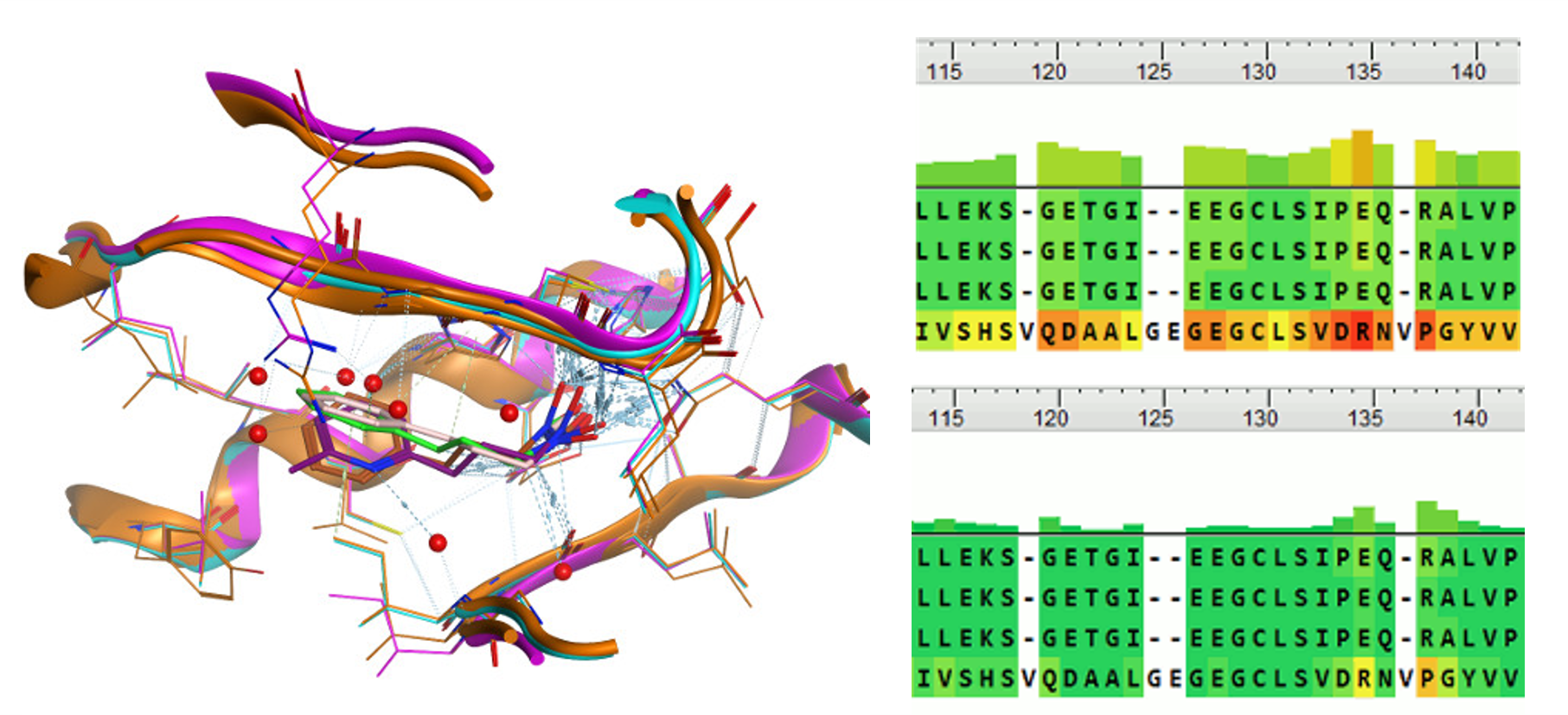
立体構造の重ね合わせと残基毎のRMSDの表示
コンセンサス解析
複数のタンパク質に保存されている配列や構造を保持領域として抽出できます。保持領域の定義には残基の一致度、主鎖または側鎖のRMSD、水分子の配置位置が利用可能です。構造保持領域のみに基づく立体構造の重ね合わせや、重ね合わせに基づいた配列アラインメントの最適化、座標平均モデルの構築機能を搭載しています。 共通する相互作用として水素結合、VDW相互作用、アレーン接触、イオン結合、ジスルフィド結合、配位結合を抽出できます。相互作用ネットワークの認識やアラインメントからの相互作用予測、タンパク質間相互作用の検出も行えます。
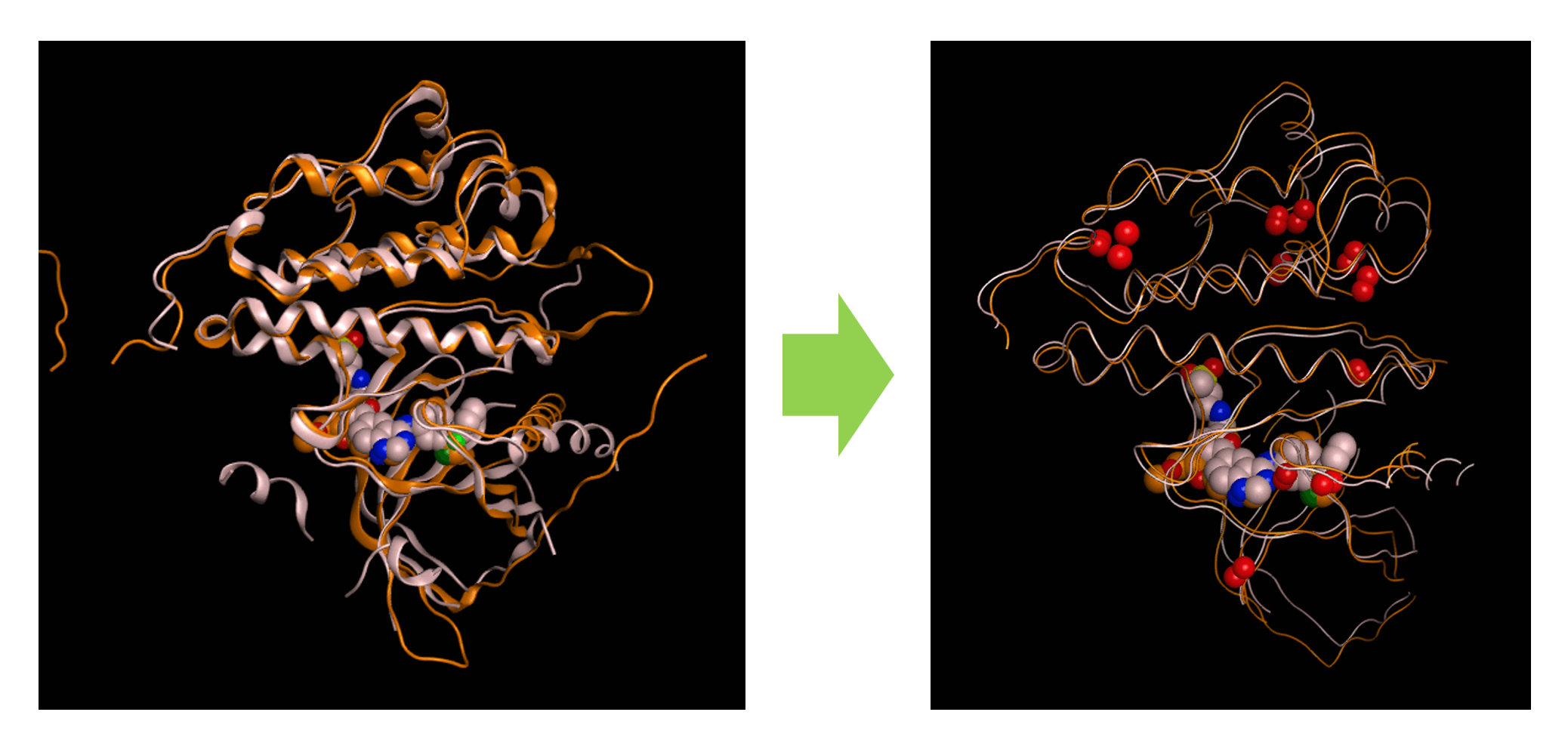
構造の重ね合わせから保存領域を抽出
title:{タンパク質立体構造データベース}
MOE Project データベース
タンパク質立体構造を用いた薬物設計には、標的タンパク質の立体構造以外に、配列、リガンド、物性、構造アノテーション、電子密度、実験値など様々な関連データの活用が重要です。MOE Project データベースは、それらの散在したデータソースを整理し集約可能なタンパク質立体構造データベースとしてまとめたものです。標的タンパク質は、リガンド結合部位などで重ね合わせされ、種、ファミリー、リガンド構造、リガンドの物性値、PLIF (Protein Ligand Interaction Fingerprint) 情報、タンパク質の構造アノテーション等を収録しています。MOE Projectデータベースからは、キーワード検索の他に、アミノ酸配列、リガンド構造、ポケット構造、相互作用等の柔軟な構造検索が可能です。以下のデータベースを標準搭載し、ユーザーによる最新データへのアップデートもできます。ユーザーによるオリジナルのMOE Project データベースの構築も可能です。
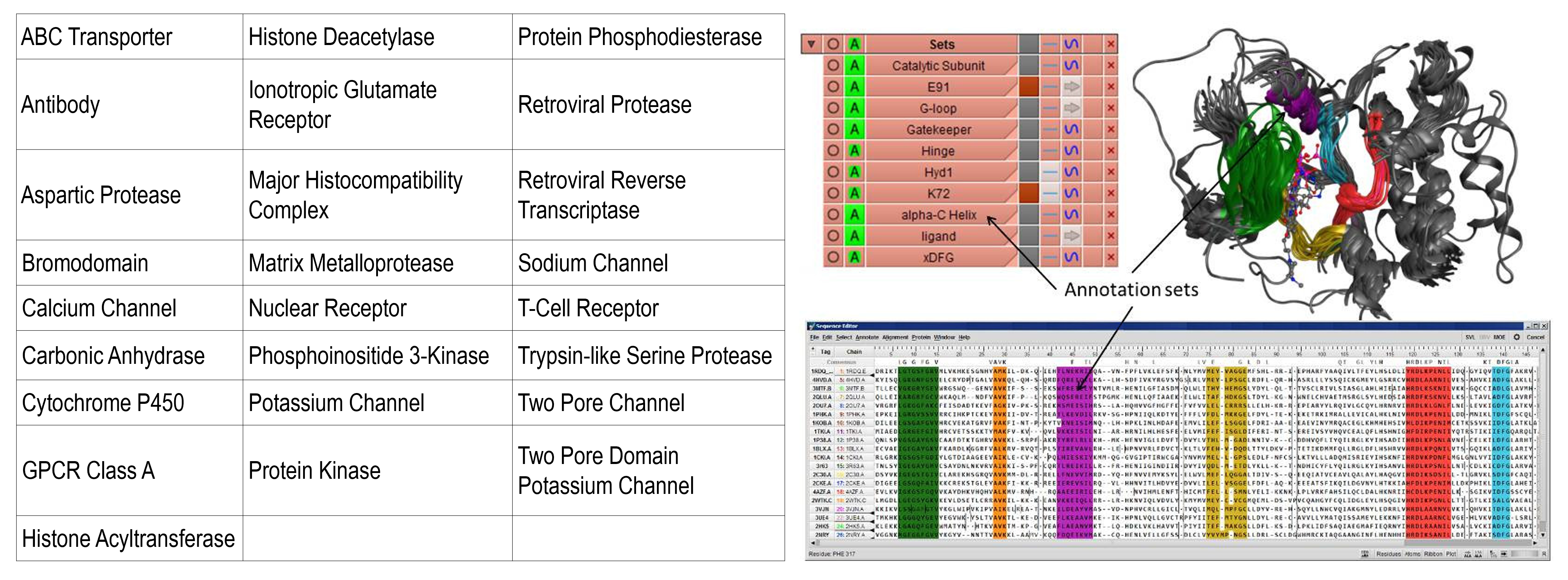
(左)MOE Project データベース一覧。(右)MOE Project データベース(Protein Kinase)の一部。活性部位で重ね合わせされており、配列と構造にアノテーション(色がついている部位)が付加されている。
タンパク質ドメインデータベースとタンパク質ファミリー配列データベース
PDBデータから構造の冗長性を排除したタンパク質ドメイン構造データベースを用意しています。これはホモロジーモデリングのテンプレートに使用します。また、タンパク質ドメイン構造データベースとUniProtの配列データを用いて、配列および立体構造ベースのクラスタリングにより作成された、タンパク質ファミリー配列データベースも用意しています。このデータベースは相同タンパク質の検索対象として利用され、遠縁の構造類似タンパク質の検出やファミリー単位の解析を実現します。
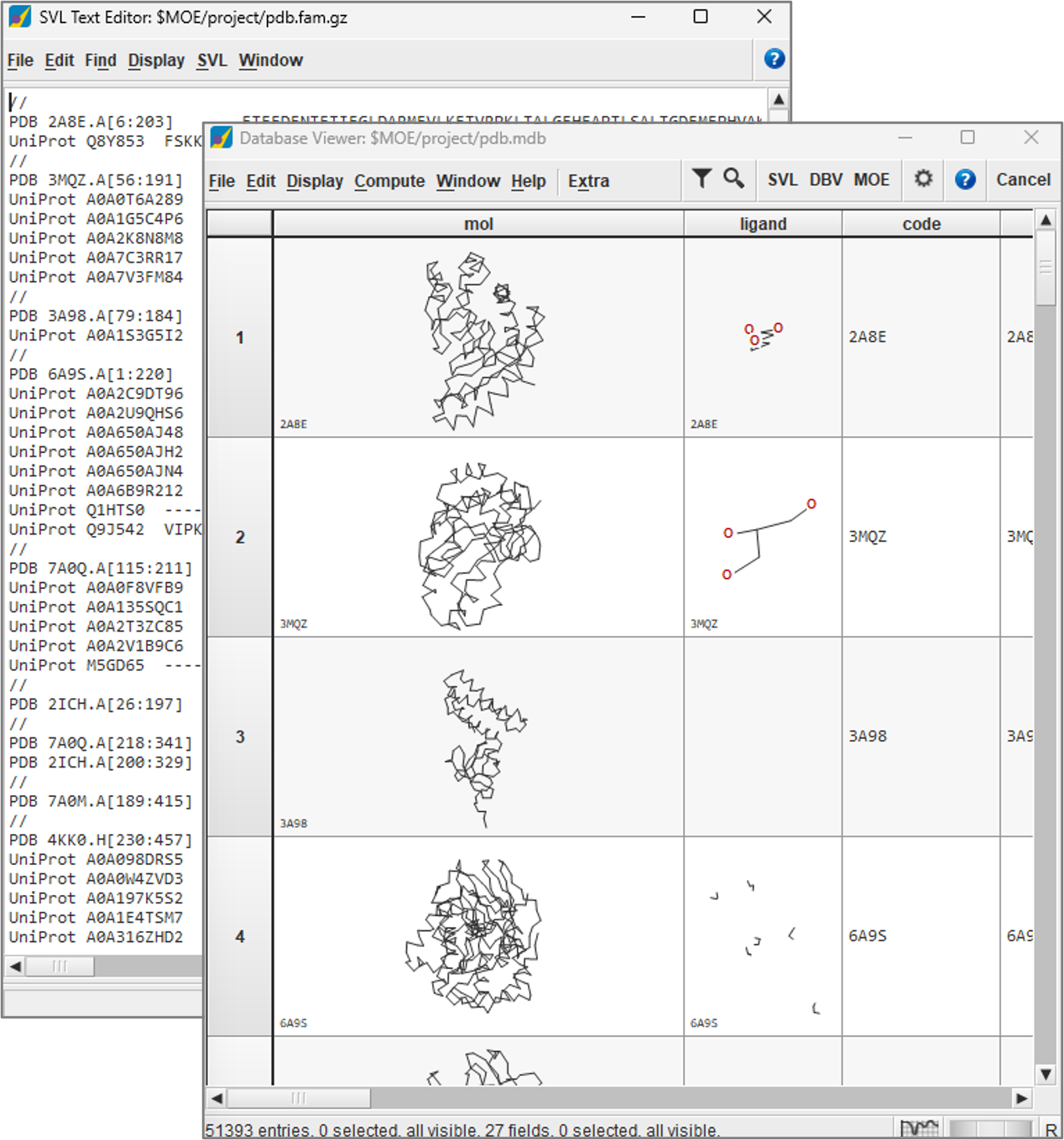
タンパク質ドメイン構造データベースとタンパク質ファミリー配列データベース
ドメインモチーフ検索
配列非依存的なタンパク質の類似構造検索が行えます。標準搭載のタンパク質立体構造データベースや、任意のタンパク質立体構造セットに対して、二次構造ベクトルの集合をモチーフ構造として検索します。この手法により、既存の検索法では検出できない遠縁のタンパク質も検出できます。また、ポケット類似構造検索などにも利用できます。
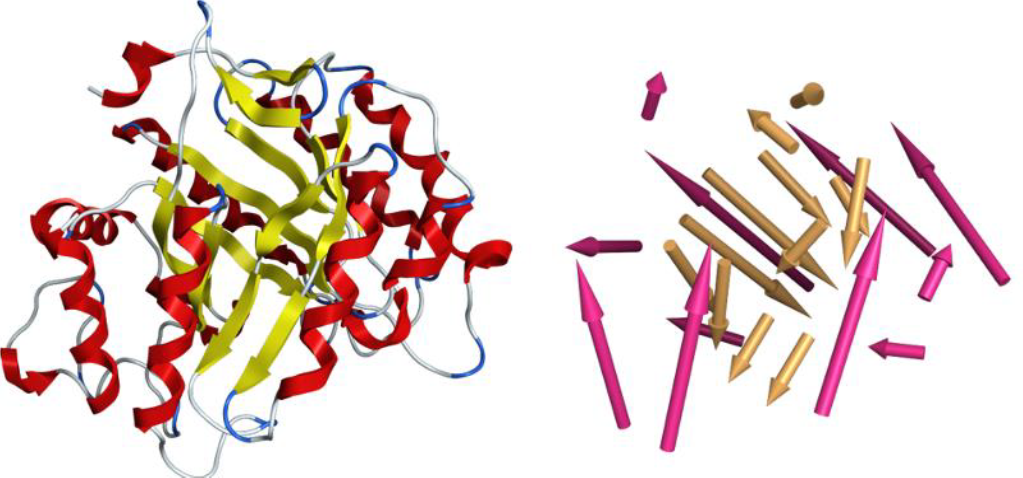
二次構造ベクトルの表示例
}:tab